Remover apenas uma pequena fração dos dados de crowdsourcing que informam as plataformas de classificação online pode mudar significativamente os resultados.
Uma empresa que deseja usar um grande modelo de linguagem (LLM) para resumir relatórios de vendas ou classificar consultas de clientes pode escolher entre centenas de LLMs únicos com dezenas de variações de modelo, cada um com desempenho ligeiramente diferente.
Para reduzir a escolha, as empresas muitas vezes recorrem às plataformas de classificação LLM, que coletam feedback do usuário sobre interações do modelo para classificar os LLMs mais recentes com base em como eles se saem em determinadas tarefas.
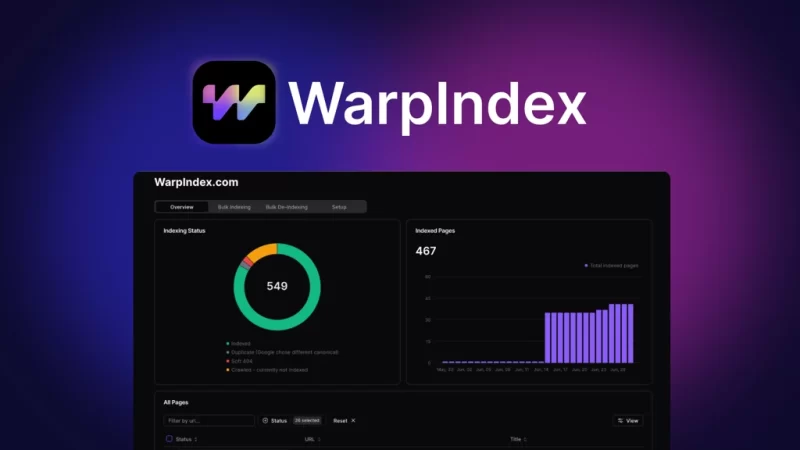





Mas pesquisadores do MIT descobriram que um punhado de interações do usuário pode distorcer os resultados, levando alguém a acreditar erroneamente que um LLM é a escolha ideal para um caso de uso específico. Seu estudo revela que a remoção de uma pequena fração de dados de crowdsourcing pode alterar quais modelos são os mais bem classificados.
Eles desenvolveram um método rápido para testar plataformas de classificação e determinar se são suscetíveis a esse problema. A técnica de avaliação identifica os votos individuais mais responsáveis por distorcer os resultados para que os usuários possam inspecionar esses votos influentes.
Os pesquisadores afirmam que esse trabalho destaca a necessidade de estratégias mais rigorosas para avaliar as classificações de modelos. Embora não tenham se concentrado na mitigação neste estudo, eles fornecem sugestões que podem melhorar a robustez dessas plataformas, como coletar feedback mais detalhado para criar as classificações.
O estudo também oferece um aviso aos usuários que podem confiar em classificações ao tomar decisões sobre LLMs que poderiam ter impactos importantes e custosos em um negócio ou organização.
“Ficamos surpresos que essas plataformas de classificação fossem tão sensíveis a esse problema. Se o LLM mais bem classificado depender apenas de dois ou três feedbacks de usuários entre dezenas de milhares, então não se pode presumir que o LLM mais bem classificado terá um desempenho consistente em relação a todos os outros LLMs quando for implantado,” diz Tamara Broderick, professora associada do Departamento de Engenharia Elétrica e Ciência da Computação (EECS) do MIT; membro do Laboratório de Sistemas de Informação e Decisão (LIDS) e do Instituto de Dados, Sistemas e Sociedade; afiliado ao Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL); e autora sênior deste estudo.
Ela é acompanhada no artigo por autoras principais e alunas de pós-graduação do EECS, Jenny Huang e Yunyi Shen, além de Dennis Wei, pesquisador sênior do IBM Research. O estudo será apresentado na Conferência Internacional sobre Representações de Aprendizado.